
Have you ever started a course, but thought it was too slow? Or too difficult? Wish you could make it go faster? Felt like you didn’t get enough practice to master the content? Adaptive learning systems seek to address these challenges.
In this article, I’ll go over what adaptive learning systems are. I cover some background on why adaptive learning systems have the structure they do. I’ll introduce a few adaptive learning systems. Then, I talk about the four elements. And how you can architect an adaptive learning system. We’ll wrap up with evaluating the pros and cons of adaptive learning.
What is an adaptive learning system?
An adaptive learning system is software where algorithms optimize the content to adjust for the learner’s goals and current state of knowledge.
In a traditional e-learning course, you will linearly follow the path an instructor creates. You watch videos, read articles, take quizzes, and practice interactive modules in a predetermined ordered. An adaptive learning system will contain the same types of materials. But the order will change for each learner. The system decides which content to show the learner based on two things:
- If the learner’s goal is only a subset of the content, the system can limit the content.
- The prior knowledge also comes into play. If the system determines the current path is too easy, the system can speed up to more challenging material. If the system finds out the current path is too difficult, the system may… intervene and review prerequisite content, reduce the challenge, or slow down the pace.
Some related topics include intelligent tutors, adaptive testing, psychometrics, personalized learning, and smart teaching. Many of these topics share algorithms and structures with adaptive learning systems.

Knowledge is a graph: neuroscience
I’m going to start with a little background. This will create context for why adaptive learning systems have the four elements below. The point for this is knowledge is a graph.
The human brain has 86 billion neurons. Every neuron has dendrites, a soma, and an axon.

- The dendrites are the input. The edges of the dendrites receive neurotransmitters from the synapse. The synapse is a gap between two neurons.
- The soma is the throughput. The soma – which contains the cell nucleus – routes the input from the dendrites.
- The axon is the output. The axon transmits an action potential – an electrical signal – to the axon terminals. A myelin sheath covers the axon to protect the signal. The axon terminals release neurotranmitters into the synapse.
Information your brain receives and processes corresponds with a neural pathway. Your brain with myelinate that pathway – strengthen the myelin around the axon to support electrical signals. Because of the strengthened myelin, this path will be more likely to fire in the future. In other words, you learn.
Even in the smallest scale, our brain is a massive graph of connected neurons. We learn and optimize by making some paths more likely to connect than other paths.
Knowledge is a graph: learning science
The strongest predictor of how we perform in a learning environment is our prior knowledge. What we already know before we start the learning experience. A notable psychology paper – 1999 Dochy, Segers, and Buehl – found prior knowledge is 81% of outcome differences between learners. Reviewing prior knowledge before showing new information impacts learning outcomes. And connecting new knowledge to prior knowledge while teaching can have a big impact too. (See Eight Ideas for sources.)
The most famous psychology paper is 1956 “The Magical Number Seven, Plus or Minus Two” by George Miller. The paper suggests that humans have a limited working memory. Miller found for simple numbers, a human could work with about seven items at once. Later researchers found for more complex information, that limit is closer to four.
Some psychologists suggest of these “four slots”, for us to learn, at least one or two must be prior knowledge. How much prior knowledge we can “load up” into one of the four slots depends on the strength of the connections in the graph. When we have both prior knowledge and new knowledge in our working memory, we associate the information. And we strengthen the connection between the two. Trying to learn new information without connecting to prior knowledge limits the strength of the memory.
In short, we learn by connecting prior knowledge to new information. And those connections form a large, endless graph of knowledge.
A few important adaptive learning systems
This section is more context, but optional. I’m not writing an thorough article about the history of these systems, but here’s some bullets:
- One of the earliest implementations was the Skinner teaching machine.
- During the 1960s and 1970s, there were several attempts at computerized instructional systems. Costs and slower machines limited the success of these systems.
- During the late 70s and early 80s, Item Response Theory enabled test makers to start work on computerized adaptive testing.
- An early and influential computerized system was the Lisp tutor, also known as LISPITS (1983) at Carnegie Mellon University.
- SuperMemo, released in 1985, incorporated spaced learning into a computerized system.
- Also in 1985 came paper for Knowledge Spaces, which forms the foundations of one of the four elements.
- ALEKS Math tutor came out in 1994, heavily promoting its use of knowledge spaces.
- In 1995, Corbett and Anderson published “Knowledge tracing”, forming the foundation for Bayesian knowledge tracing models.
- Some important software includes AutoTutor, ACT-R, and Cognitive Tutor Authoring Tools.
- Knewton is an example of contemporary adaptive learning systems. Kaplan and Pearson both use Knewton to provide adaptive learning experiences.
The four elements
Most adaptive learning systems today have these four elements. The terms change and so do their scope. But you will almost always find all four elements.
These elements are:
- The expert – a graphical model of the “ideal” state, of everything the person could learn using this system.
- The learner – a model of the learner’s current state, which shows how likely the learner is to know each of the nodes in the expert graph.
- The tutor – the algorithms that determines what content to show and when. The expert model and the learner model inform the tutor. The tutor seeks to optimize content for relevance, challenge, and efficiency.
- The interface – which is how to display the learning experience to the learner. In many adaptive learning experience, the interface changes based on the learner model and the tutor’s goals.
Let’s go into each element.

The expert — the big graph of everything
The expert model is a large, connected graph of everything you want the learners to know. As the name suggests, you have an expert on the topic – or experts on topics – create the model. This model is static. The expert model only changes when the scope of learning outcomes change. Or when problems and opportunities to refine the adaptive learning system arises. Most of the work of the expert model is at the beginning of building a new learning experience. The adaptive learning system will access the expert model to compare the learner’s current state with the expert model. The system will also access the expert model to determine which learning experience to focus on next.
Usually, a team of experts will define the scope of learning outcomes. Each node in the expert model should have the following attributes:
- A name
- A short description, which indicates which skills are under test and what is outside the scope
- A list of prerequisite nodes – these form the “edges” of the graph. These prerequisites cannot form a “cycle” – a loop of nodes.
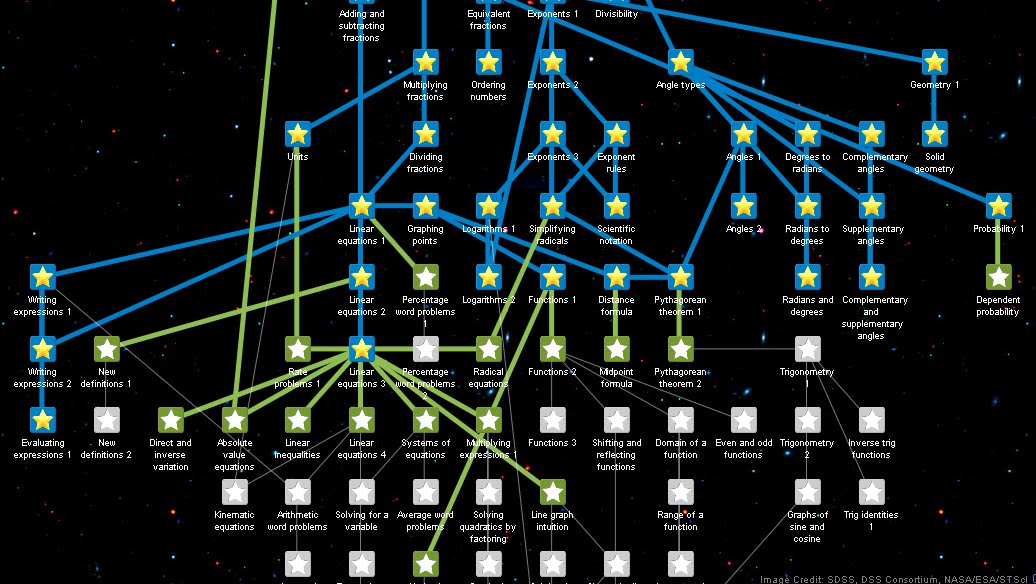
Expert models perform better when each node is small and narrowly defined. For example, each skill in Bloom’s taxonomy – recognition, understanding, application, analysis, synthesis, and evaluation – could each be its own node in the expert model. The combination of two underlying skills should also be a separate node.
There is an endless number of formats you could use to create an expert model, such as XML, JSON, CSV, or YAML. It can help to be able to display the expert model graphically for review.
Some systems will automatically generate an expert model by querying experts in a series of questions, like a wizard. Others will cluster existing learning content, using algorithms like k-means clustering. You may want to review the wikipedia article on Knowledge spaces for a more mathematical description.

The learner — where you are versus where you want to be
The learner element is a model of the learner’s current state of ability. So for each given node in the expert graph, the learner model has a probability associated with it: 1-99%. The system updates this graph every time the learner performs an activity. If a learner answers a question correctly, the probability increases. If the learner answers incorrectly, the probability decreases. Each learner has their own learner model. So each time there’s a new learner in the system, there’s a new learner model. Later, the tutor will use the learner model to decide how to order the learning content.
There’s many algorithms for updating the learner model. Knowledge spaces suggest that as a learner develops a skill, the probabilities for related skills should also adjust. Some adaptive learning systems use simple heuristic models for updating skill probabilities. In item response theory, the probability updates along a sigmoid curve. In Bayesian knowledge tracing, this curve has a more conservative shape. Each model tends to account for these factors:
- Before the learner does anything, what do we estimate the probability to be?
- How likely is a learner to guess the right answer if they don’t know the skill?
- How likely is a learner to slip up even if they know the skill?
- How likely is the learner to have “learned” the skill after seeing the item?
- How likely does this activity categorize the learner as skilled or unskilled?
- How difficult will this item be for this particular learner?
For both item response theory and Bayesian knowledge tracing, you’ll need a means to estimate these parameters. This is one of the most rapidly developing areas in adaptive learning systems, so I can’t make any specific recommendations yet. There’s also researchers creating models with classic machine learning, such as neural networks.

The tutor — what to show when
The tutor chooses which order to select the activities the learner will engage. After each update to the learner model, the tutor will update the path it will take to optimize for that learner. The goal of the tutor is to get the learner to a complete expert graph in the smallest amount of time. Some systems allow learners to focus only on some areas while ignoring the rest. As the learner model is unique per learner, so too is the paths the tutor will take. While the expert and learner elements are data with some algorithms, the tutor is algorithms with some data.
The tutor may decide both which skills to focus on and which activities to have the learner perform. For the skills to focus on, the tutor will often choose skills with the largest impact on the larger graph. This often means focusing on more elementary skills before more advanced skills. For activities:
- The tutor will try to choose the most relevant activities to the learner
- The tutor will choose activities that are challenging, but not too difficult for the learner.
- The tutor will try to choose activities in a way that reduce the total time towards mastery.
Simple adaptive learning tutors may choose activities within a skill at random. Item response theory based tutors emphasize choosing activities that are challenging. In Bayesian knowledge tracing models the market has many different tutor algorithms. Researchers have focused more on the expert and learner elements. So we don’t know what produces the best learning outcomes for the tutor element.

The interface — how to show it
Some adaptive learning systems will change the user interface. As the learner is less familiar with a skill, the interface would reduce and focus more on the task at hand. As learner ability grows, more of the full interface comes together. Some call this process “scaffolding”.
In some systems, learners may ask for and receive hints. When to offer hints and the depth of those hints can adjust based on learner ability.
There’s also some other questions like:
- Do you display the expert graph to the learner?
- Do you display their progress on all skills? How?
- Do you display their progress on specific skills? How?
- Does the learner get choices in learning content? Or does the system decide everything?
Depending on the needs of the system, some of these items may impact learning outcomes.

How do we know if adaptive learning is any good?
As these systems come from academia, we have a significant amount of data and history with each system.
Human individual tutoring has the strongest learning outcomes. This is a common finding in educational research. So far, no computerized adaptive learning system has outperformed human one-on-one tutoring.
Researchers have investigated classroom learning alone, computerized adaptive learning alone, as well as combined classroom and adaptive learning. A 2016 paper “Effectiveness of Intelligent Tutoring Systems” provides a meta analysis of these studies. Adaptive learning systems usually outperform traditional classroom learning. Combined with classroom learning, adaptive learning systems create a positive effect, but there are some limitations.
Adaptive systems do particularly well with instant feedback and ensuring skill mastery. Investigators note some areas for improvement:
- The cost of developing content for these systems is high.
- These systems often can’t contextualize learning the way a human can.
- Adaptive learning systems can feel more challenging, which can reduce learner motivation.
Wrap up
Welp, I’ve nerded out now. I’ve covered what adaptive learning systems are. I’ve provided some context for the design of these systems. A touch of history. I’ve covered the four major elements: the expert, the learner, the tutor, and the interface. Hopefully it wasn’t too technical.